What is Amazon DynamoDB
Amazon DynamoDB is a fully managed NoSQL database service that provides
fast and predictable performance with seamless scalability.
- Auto scale throughput capacity without downtime or performance degradation.
- Monitor resource utilization and performance metrics using AWS management console.
- Create on-demand backups and enable point-in-time recovery for your Amazon DynamoDB tables.
- Use Time To Live (TTL) to automatically delete expired items, saving cost.
- SSD disks
- Data spread across multiple servers across multiple AZs in an AWS region.
- Use global tables to keep DynamoDB tables in sync across AWS Regions.
In DynamoDB, tables, items, and attributes are the core components that you work with. A table is a collection of items, and each item is a collection of attributes. DynamoDB uses primary keys to uniquely identify each item in a table and secondary indexes to provide more querying flexibility. You can use DynamoDB Streams to capture data modification events in DynamoDB tables.
For example table named People has many items each of which is a person.
Each person has a lastName attribute as shown below:
AWS Dynamo DB - People Table Illustration

AWS Dynamo DB - People Table Illustration. Source: docs.aws.amazon.com/amazondynamodb
-
Each item in the table has a unique identifier, or primary key, that distinguishes the item from all of the others in the table. In the People table, the primary key consists of one attribute (PersonID). You could define a primary key comprising of more than one attribute.
-
Other than the primary key, the People table is schemaless, which means that neither the attributes nor their data types need to be defined beforehand. Each item can have its own distinct attributes.
-
Most of the attributes are scalar, which means that they can have only one value. Strings and numbers are common examples of scalars.
-
Some of the items have a nested attribute (Address). DynamoDB supports nested attributes up to 32 levels deep.
-
Each primary key attribute must be a scalar (meaning that it can hold only a single value). The only data types allowed for primary key attributes are string, number, or binary.
-
DynamoDB supports two different kinds of primary keys:
-
Partition key – A simple primary key, composed of one attribute known as the partition key.
-
Partition key and sort key – Referred to as a composite primary key, this type of key is composed of two attributes. The first attribute is the partition key, and the second attribute is the sort key.
-
Secondary Indexes
You can create one or more secondary indexes on a table. A secondary index lets you query the data in the table using an alternate key, in addition to queries against the primary key. After you create a secondary index on a table, you can read data from the index in much the same way as you do from the table. DynamoDB supports two kinds of indexes:
-
Global secondary index – An index with a partition key and sort key that can be different from those on the table.
-
Local secondary index – An index that has the same partition key as the table, but a different sort key.
When you create an index, you specify which attributes will be copied, or projected, from the base table to the index. At a minimum, DynamoDB projects the key attributes from the base table into the index.
DynamoDB Streams
DynamoDB Streams is an optional feature that captures data modification events
in DynamoDB tables. The data about these events appear in the stream in
near-real time, and in the order that the events occurred.
-
If enabled, DynamoDB Streams writes a stream record whenever one of the following events occurs:
- A new item is added to the table: The stream captures an image of the entire item, including all of its attributes.
- An item is updated: The stream captures the “before” and “after” image of any attributes that were modified in the item.
- An item is deleted from the table: The stream captures an image of the entire item before it was deleted.
-
Each stream record also contains the name of the table, the event timestamp, and other metadata.
-
Stream records have a lifetime of 24 hours; after that, they are automatically removed from the stream.
Read Consistency
- Tables are region specific. If you have a table called
Peoplein the
us-east-2 Region and another table named People in the us-west-2 Region,
these are considered two entirely separate tables.
-
DynamoDB supports eventually consistent and strongly consistent reads.
-
Strongly consistent reads are not supported on global secondary indexes.
-
DynamoDB uses eventually consistent reads, unless you specify otherwise. Read
operations (such as GetItem, Query, and Scan) provide a ConsistentRead
parameter. If you set this parameter to true, DynamoDB uses strongly consistent reads during the operation.
Read/Write Capacity Mode
The read/write capacity mode controls how you are charged for read and write throughput and how you manage capacity. You can set the read/write capacity mode when creating a table or you can change it later. Amazon DynamoDB has two read/write capacity modes:
-
On-demand Use cases:
- You create new tables with unknown workloads.
- You have unpredictable application traffic.
- You prefer the ease of paying for only what you use.
-
Provisioned (default, free-tier eligible)
- You have predictable application traffic.
- You run applications whose traffic is consistent or ramps gradually.
- You can forecast capacity requirements to control costs.
Partitions
Amazon DynamoDB stores data in partitions. A partition is an allocation of storage for a table, backed by solid state drives (SSDs) and automatically replicated across multiple Availability Zones within an AWS Region. Partition management is handled entirely by DynamoDB—you never have to manage partitions yourself.
DynamoDB is a web service, and interactions with it are stateless. Applications do not need to maintain persistent network connections. Instead, interaction with DynamoDB occurs using HTTP(S) requests and responses.
Every request to DynamoDB must be accompanied by a cryptographic signature, which authenticates that particular request. The AWS SDKs provide all of the logic necessary for creating signatures and signing requests.
In DynamoDB, authorization is handled by AWS Identity and Access Management (IAM). You can write an IAM policy to grant permissions on a DynamoDB resource (such as a table), and then allow IAM users and roles to use that policy. IAM also features fine-grained access control for individual data items in DynamoDB tables.
Backup and Restore
Amazon DynamoDB offers several features to help support your data resiliency and backup needs.
On-Demand Backup and Restore
You can create on-demand backups for your Amazon DynamoDB tables or enable continuous backups with point-in-time recovery.
Scales without degrading the performance or availability of your applications.
Complete backups in seconds regardless of table size.
Point-in-Time Recovery
DynamoDB maintains automatic incremental backups of your table. (35 days retention period)
With point-in-time recovery, you don’t have to worry about creating, maintaining, or scheduling on-demand backups.
Global Tables
Global Table Concepts
A global table is a collection of one or more replica tables, all owned by a single AWS account.
A replica table (or replica, for short) is a single DynamoDB table that functions as a part of a global table. Each replica stores the same set of data items. Any given global table can only have one replica table per AWS Region.
When you create a DynamoDB global table, it consists of multiple replica tables (one per Region) that DynamoDB treats as a single unit. Every replica has the same table name and the same primary key schema. When an application writes data to a replica table in one Region, DynamoDB propagates the write to the other replica tables in the other AWS Regions automatically.
Consistency and Conflict Resolution
Any changes made to any item in any replica table are replicated to all the other replicas within the same global table, usually within a second. An application can read and write data to any replica table.
DynamoDB does not support strongly consistent reads across Regions.
For concurrent updates, DynamoDB uses last writer wins strategy for reconciliation and to help ensure eventual consistency.
Availability and Durability
If a single AWS Region becomes isolated or degraded, your application can redirect to a different Region and perform reads and writes against a different replica table. You can apply custom business logic to determine when to redirect requests to other Regions.
If a Region becomes isolated or degraded, DynamoDB keeps track of any writes that have been performed but have not yet been propagated to all of the replica tables. When the Region comes back online, DynamoDB resumes propagating any pending writes from that Region to the replica tables in other Regions. It also resumes propagating writes from other replica tables to the Region that is now back online.
Best Practices and Requirements for Managing Capacity
It is important that the replica tables and secondary indexes in your global table have identical write capacity settings to ensure proper replication of data.
Use on-demand capacity or enable autoscaling on the table, to ensure you always have sufficient capacity to perform replicated writes to all regions of the global table.
DynamoDB Transactions
Idempotency
You can optionally include a client token when you make a TransactWriteItems call to ensure that the request is idempotent. If the original TransactWriteItems call was successful, the subsequent TransactWriteItems calls with the same client token return successfully without making any changes.
A client token is valid for 10 minutes after the request that uses it finishes.
If you repeat a request with the same client token within the 10-minute idempotency window but change some other request parameter, DynamoDB returns an IdempotentParameterMismatch exception.
Global tables
Transactional operations provide atomicity, consistency, isolation, and durability (ACID) guarantees only within the region where the write is made originally.
Transactions are not supported across regions in global tables, as changes will only be replicated to other regions once they have been committed in the source region.
IAM
You can use AWS Identity and Access Management (IAM) to restrict the actions that transactional operations can perform in Amazon DynamoDB.
DynamoDB Acceleration
DynamoDB Accelerator (DAX) is designed to work together with DynamoDB, to seamlessly add a caching layer to your applications.
DAX is designed to run within an Amazon Virtual Private Cloud (Amazon VPC) environment. The Amazon VPC service defines a virtual network that closely resembles a traditional data center. With a VPC, you have control over its IP address range, subnets, routing tables, network gateways, and security settings. You can launch a DAX cluster in your virtual network and control access to the cluster by using Amazon VPC security groups.
High level overview of DAX
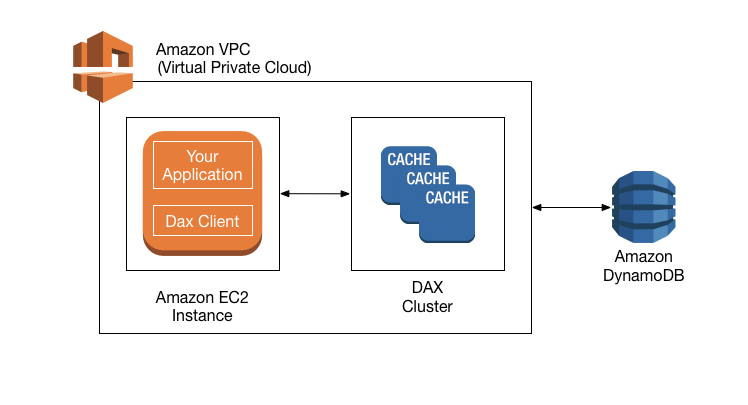
High level overview of DAX. Source: docs.aws.amazon.com/amazondynamodb
A DAX cluster consists of one or more nodes. Each node runs its own instance of the DAX caching software. One of the nodes serves as the primary node for the cluster. Additional nodes (if present) serve as read replicas.
Your application can access DAX by specifying the endpoint for the DAX cluster. The DAX client software works with the cluster endpoint to perform intelligent load balancing and routing. Incoming requests are evenly distributed across all of the nodes in the cluster.
Read Operations
If the request specifies:
-
Eventually consistent reads (the default behavior), it tries to read the item from DAX, passing through to DynamoDB only if DAX does not have the item.
-
Strongly consistent reads, DAX passes the request through to DynamoDB. The results from DynamoDB are not cached in DAX. Instead, they are simply returned to the application.
Write Operations
Data is first written to the DynamoDB table, and then to the DAX cluster. The operation is successful only if the data is successfully written to both the table and to DAX.
Item Cache
DAX maintains an item cache to store the results from GetItem and BatchGetItem operations. The items in the cache represent eventually consistent data from DynamoDB, and are stored by their primary key values.
The item cache has a Time to Live (TTL) setting, which is 5 minutes by default.
You can specify the TTL setting for the item cache when you create a new DAX cluster.
DAX maintains a least recently used (LRU) list for the item cache. If the item cache becomes full, DAX evicts older items (even if they haven’t expired yet) to make room for new items. The LRU algorithm is always enabled for the item cache and is not user-configurable.
Query Cache
DAX also maintains a query cache to store the results from Query and Scan operations. The items in this cache represent result sets from queries and scans on DynamoDB tables. These result sets are stored by their parameter values.
You can specify the TTL setting for the query cache when you create a new DAX cluster.
DAX maintains an LRU list for the query cache. If the query cache becomes full, DAX evicts older result sets (even if they have not expired yet) to make room for new result sets. The LRU algorithm is always enabled for the query cache, and is not user-configurable.
DAX Cluster
For production usage, Amazon strongly recommends using DAX with at least three nodes, where each node is placed in different Availability Zones. Three nodes are required for a DAX cluster to be fault-tolerant.
A DAX cluster in an AWS Region can only interact with DynamoDB tables that are in the same Region. You should launch a DAX cluster for each region where you have DynamoDB tables.
Parameter group - Parameter groups are used to manage runtime settings for DAX clusters. TTL policy for cached data is an example of a parameter.
Security Group - When you launch a cluster in your VPC, you add an ingress rule to your security group to allow incoming network traffic. The ingress rule specifies the protocol (TCP) and port number (8111) for your cluster. After you add this rule to your security group, the applications that are running within your VPC can access the DAX cluster.
Cluster Endpoint - Every DAX cluster provides a cluster endpoint for use by your application. By accessing the cluster using its endpoint, your application does not need to know the hostnames and port numbers of individual nodes in the cluster.
Node Endpoint - Each of the individual nodes in a DAX cluster has its own hostname and point number.
Subnet Groups - When you create a DAX cluster, you must specify a subnet group. A subnet group is a collection of subnets (typically private) that you can designate for your clusters running in an Amazon VPC environment. You can use subnet groups to grant cluster access from Amazon EC2 instances running on specific subnets. Access to DAX cluster nodes is restricted to applications running on Amazon EC2 instances within an Amazon VPC environment.
Events - DAX records significant events within your clusters, such as a failure to add a node, success in adding a node, or changes to security groups. Events could be sent to an SNS topic.
Maintenance Window - Every cluster has a weekly maintenance window during which any system changes are applied.
Managing DAX Clusters
- Horizontal Scaling With horizontal scaling, you can `improve throughput
for read operations` by adding more read replicas to the cluster. A single DAX cluster supports up to 10 read replicas, and you can add or remove replicas while the cluster is running.
-
Vertical Scaling Your application might benefit from a larger node type if:
- You have a large working set of data
- Your DAX cluster has a high rate of write operations or cache misses
You can’t modify the node types on a running DAX cluster. Instead, you must create a new cluster with the desired node type.
Monitoring DAX Clusters
-
Automated Monitoring - You can use the following automated monitoring tools to watch DAX and report when something is wrong:
-
Amazon CloudWatch Alarms– Watch a single metric over a time period that you specify, and perform one or more actions based on the value of the metric relative to a given threshold over a number of time periods. The action is a notification sent to an Amazon Simple Notification Service (Amazon SNS) topic or Amazon EC2 Auto Scaling policy. CloudWatch alarms do not invoke actions simply because they are in a particular state; the state must have changed and been maintained for a specified number of periods. -
Amazon CloudWatch Logs– Monitor, store, and access your log files from AWS CloudTrail or other sources. -
Amazon CloudWatch Events– Match events and route them to one or more target functions or streams to make changes, capture state information, and take corrective action. -
AWS CloudTrail Log Monitoring– Share log files between accounts, monitor CloudTrail log files in real time by sending them to CloudWatch Logs, write log processing applications in Java, and validate that your log files have not changed after delivery by CloudTrail.
-
Access Control
Both DAX and DynamoDB use AWS Identity and Access Management (IAM) to implement their respective security policies, but the security models for DAX and DynamoDB are different.
With DynamoDB, you can create IAM policies that limit the actions a user can perform on individual DynamoDB resources. By comparison, the DAX security model focuses on cluster security, and the ability of the cluster to perform DynamoDB API actions on your behalf.
If you are currently using IAM roles and policies to restrict access to DynamoDB tables data, then the use of DAX can subvert those policies. For example, a user could have access to a DynamoDB table via DAX but not have explicit access to the same table accessing DynamoDB directly.
DAX does not enforce user-level separation on data in DynamoDB. Instead, users inherit the permissions of the DAX cluster’s IAM policy when they access that cluster. Thus, only permissions in the DAX cluster’s IAM policy, and no other, are recognized.
If you require isolation, we recommend that you create additional DAX clusters and scope the IAM policy for each cluster accordingly
-
IAM Service Role for DAX - When you create a DAX cluster, you must associate the cluster with an IAM role. This is known as the service role for the cluster. When you create a service role, you must specify a trust relationship between the service and the DAX service itself. A trust relationship determines which entities can assume a role and make use of its permissions. The DynamoDB API actions that are allowed are described in an IAM policy document, which you attach to the service role.
-
IAM Policy to Allow DAX Cluster Access -After you create a DAX cluster, you need to grant permissions to an IAM user so that the user can access the DAX cluster. Create an IAM policy that defines the DAX clusters and the DAX API actions that the policy recipient can access/perform. The attach the policy to any IAM user/role you want.
DAX Encryption at Rest
DAX encryption at rest is not supported for dax.r3.* node types.
You cannot enable or disable encryption at rest after a cluster has been created. You must re-create the cluster to enable encryption at rest if it was not enabled at creation.
Accessing DAX Across AWS Accounts
Allow account B access DAX cluster running in Account A. (Requires admin access in both AWS accounts)
- Launch an EC2 instance in account B with an IAM role from account B.
- Use temporary security credentials from the EC2 instance to assume an IAM role from account A.
- Make application calls over an Amazon VPC peering connection to the DAX cluster in account A
DAX Cluster Sizing Guide
It’s important to scale your DAX cluster appropriately for your workload, moreover you should periodically revisit your scaling decisions to make sure that they are still appropriate. The process typically follows these steps:
-
Estimating traffic. In this step, you make predictions about the volume of traffic that your application will send to DAX, the nature of the traffic (read vs. write operations), and the expected cache hit rate.
-
Load testing. In this step, you create a cluster and send traffic to it mirroring your estimates from the previous step. Repeat this step until you find a suitable cluster configuration.
-
Production monitoring. While your application is using DAX in production, you should monitor the cluster to continuously validate that it is still scaled correctly as your workload changes over time.
Some DynamoDB Tools
NoSQL Workbench for Amazon DynamoDB
NoSQL Workbench for Amazon DynamoDB is a cross-platform client-side application for modern database development and operations and is available for Windows and macOS. NoSQL Workbench is a unified visual tool that provides data modeling, data visualization, and query development features to help you design, create, query, and manage DynamoDB tables.
Analyzing Data Access Using CloudWatch Contributor Insights for DynamoDB
Amazon CloudWatch Contributor Insights for Amazon DynamoDB is a diagnostic tool for identifying the most frequently accessed and throttled keys in your table or index at a glance. This tool uses CloudWatch Contributor Insights. By enabling CloudWatch Contributor Insights for DynamoDB on a table or global secondary index, you can view the most accessed and throttled items in those resources.
Security
Data Protection
All user data stored in Amazon DynamoDB is fully encrypted at rest, using encryption keys stored in AWS KMS. When creating a new table, you can choose one of the following customer master keys (CMK) to encrypt your table:
-
AWS owned CMK – Default encryption type. The key is owned by DynamoDB (no additional charge).
-
AWS managed CMK – The key is stored in your account and is managed by AWS KMS (AWS KMS charges apply).
-
Customer managed CMK – The key is stored in your account and is created, owned, and managed by you. You have full control over the CMK (AWS KMS charges apply).
You can switch between the AWS owned CMK, AWS managed CMK, and customer managed CMK at any given time.
DynamoDB continues to deliver the same single-digit millisecond latency that you have come to expect, and all DynamoDB queries work seamlessly on your encrypted data.
DynamoDB doesn’t call AWS KMS for every DynamoDB operation. The key is refreshed once every 5 minutes per client connection with active traffic. Ensure that you have configured the SDK to reuse connections. Otherwise, you will experience latencies from DynamoDB having to reestablish new AWS KMS cache entries for each DynamoDB operation
Server-side encryption at rest is enabled on all DynamoDB table data and cannot be disabled.
DynamoDB streams are always encrypted with a table-level encryption key.
Local secondary indexes and global secondary indexes are encrypted using the same key as the base table.
Global tables can be encrypted using an AWS owned CMK or AWS managed CMK.
You cannot use a customer managed CMK:
- To encrypt global tables.
- With DynamoDB Accelerator (DAX) clusters
Preventive Security Best Practices
-
Encryption at rest.
-
Use IAM roles to authenticate access to DynamoDB.
-
Use IAM policies for DynamoDB base authorization.
-
Use IAM policy conditions for fine-grained access control.
-
Use a VPC endpoint and policies to access DynamoDB - If you only require access to DynamoDB from within a virtual private cloud (VPC), you should use a VPC endpoint to limit access from only the required VPC. Doing this prevents that traffic from traversing the open internet
Using a VPC endpoint for DynamoDB allows you to control and limit access using the following:
-
VPC endpoint policies– These policies are applied on the DynamoDB VPC endpoint. They allow you to control and limit API access to the DynamoDB table. -
IAM policies– By using the aws:sourceVpce condition on policies attached to IAM users, groups, or roles, you can enforce that all access to the DynamoDB table is via the specified VPC endpoint.
-
-
Consider client-side encryption - The Amazon DynamoDB Encryption Client is a software library that helps you protect your table data before you send it to DynamoDB.
__Detective Security Best Practices __
-
Use AWS CloudTrail to monitor AWS managed KMS key usage
-
Use CloudTrail to monitor DynamoDB control-plane operations
-
Consider using DynamoDB Streams to monitor modify/update data-plane operations
-
Monitor DynamoDB configuration with AWS Config
-
Monitor DynamoDB compliance with AWS Config rules
-
Tag your DynamoDB resources for identification and automation
Best Practices
The primary key that uniquely identifies each item in an Amazon DynamoDB table can be simple (a partition key only) or composite (a partition key combined with a sort key).
-
Design your application for uniform activity across all logical partition keys in the table and its secondary indexes.
-
Prefer global secondary indexes over local secondary indexes. The exception is, for:
- Strong consistency - local secondary indexes. Eventual consistency - global secondary indexes.
-
Keep the number of indexes to a minimum. Don’t create secondary indexes on attributes that you don’t query often.
Time Series Data
For most applications, a single table is all you need. However, for time series data, you can often best handle it by using one table per application per period. Consider a typical time series scenario, where you want to track a high volume of events. Your write access pattern is that all the events being recorded have today’s date. Your read access pattern might be to read today’s events most frequently, yesterday’s events much less frequently, and then older events very little at all. One way to handle this is by building the current date and time into the primary key.
The following design pattern often handles this kind of scenario effectively:
-
Create one table per period, provisioned with the required read and write capacity and the required indexes.
-
Before the end of each period, prebuild the table for the next period. Just as the current period ends, direct event traffic to the new table. You can assign names to these tables that specify the periods they have recorded.
-
As soon as a table is no longer being written to, reduce its provisioned write capacity to a lower value (for example, 1 WCU), and provision whatever read capacity is appropriate. Reduce the provisioned read capacity of earlier tables as they age. You might choose to archive or delete the tables whose contents are rarely or never needed.
Relational Modeling
When your business requires low-latency response to high-traffic queries, taking advantage of a NoSQL system generally makes technical and economic sense. Amazon DynamoDB helps solve the problems that limit relational system scalability by avoiding them.
A relational database system does not scale well for the following reasons:
-
It normalizes data and stores it on multiple tables that require multiple queries to write to disk.
-
It generally incurs the performance costs of an ACID-compliant transaction system.
-
It uses expensive joins to reassemble required views of query results.
DynamoDB scales well for these reasons:
-
Schema flexibility lets DynamoDB store complex hierarchical data within a single item.
-
Composite key design lets it store related items close together on the same table.
Integrating with other AWS Services
- Amazon Cognito Avoid hardcoding your AWS credentials. Rather use Amazon Cognito as it uses
IAM roles to generate temporary credentials for your application’s authenticated and unauthenticated users.
- Amazon Redshift When you copy data from a DynamoDB table into Amazon Redshift, you can perform
complex data analysis queries on that data, including joins with other tables in your Amazon Redshift cluster.
- Amazon EMR Amazon DynamoDB is integrated with Apache Hive, a data
warehousing application that runs on Amazon EMR. Hive can read and write data in DynamoDB tables, allowing you to:
- Query live DynamoDB data using a SQL-like language (HiveQL).
- Copy data from a DynamoDB table to an Amazon S3 bucket, and vice-versa.
- Copy data from a DynamoDB table into Hadoop Distributed File System (HDFS), and vice-versa.
- Perform join operations on DynamoDB tables.
FAQs
Q: How am I charged for my use of DynamoDB?
Data storage.Standard internet transfer fees.Read and write throughput- Each DynamoDB table has provisioned read-throughput and write-throughput associated with it. You are billed by the hour for that throughput capacity if you exceed the free tier. Note that you arecharged by the hour for the throughput capacity, whether or not you are sending requests to your table.
Q: What is the maximum and minimum throughput I can provision for a single DynamoDB table?
Maximum- practically unlimited throughput per DynamoDB table.Minimum- 1 write capacity unit and 1 read capacity unit for both auto scaling and manual throughput provisioning.
Takeaways
-
Create on-demand backups and enable point-in-time recovery for your Amazon DynamoDB tables.
-
Use Time To Live (TTL) to automatically delete expired items, saving cost.
-
Data spread across multiple servers across multiple AZs in an AWS region.
-
Use global tables to keep DynamoDB tables in sync across AWS Regions.
-
Global secondary index – An index with a partition key and sort key that can be different from those on the table.
-
Local secondary index – An index that has the same partition key as the table, but a different sort key.
DynamoDB Streams - Optional feature that captures data modification events
in DynamoDB tables. near-real time, and in the order that the events occurred.
-
Stream records have a lifetime of 24 hours; after that, they are automatically removed from the stream.
-
Tables are region specific. If you have a table called
Peoplein the
us-east-2 Region and another table named People in the us-west-2 Region,
these are considered two entirely separate tables.
-
Strongly consistent reads are not supported on global secondary indexes.
-
DynamoDB is a web service, and interactions with it are stateless, HTTP(S) requests and responses.
-
Every request to DynamoDB must be accompanied by a cryptographic signature, which authenticates that particular request. The AWS SDKs provide all of the logic necessary for creating signatures and signing requests.
-
On-Demand Backup and Restore - Complete backups in seconds regardless of table size. Scales without degrading the performance or availability of your applications.
-
Point-in-Time Recovery - Automatic with 35 days retention period.
-
A DynamoDB global table consists of multiple replica tables (one per Region).
Every replica has the same table name and the same primary key schema. Writes are propagated to other replicas in other AWS Regions automatically, usually within One second.
- DynamoDB does not support strongly consistent reads across Regions.
Best Practices and Requirements for Managing Capacity
-
Ensure replica tables and secondary indexes in your global table have identical write capacity
-
Use on-demand capacity or enable autoscaling on the table
-
You can optionally include a client token when you make a
TransactWriteItemscall to ensure that the request is idempotent. -
A client token is valid for 10 minutes after the request that uses it finishes.
-
Transactions are not supported across regions in global tables.
-
DynamoDB Accelerator (DAX) is designed to work together with DynamoDB, to seamlessly add a caching layer to your applications.
-
A DAX cluster in an AWS Region can only interact with DynamoDB tables that are in the same Region.
-
Parameter group- Parameter groups are used to manage runtime settings for DAX clusters. -
Security Group- When you launch a cluster in your VPC, you add an ingress rule to your security group to allow incoming network traffic forTCPport8111. -
Access to DAX cluster nodes is restricted to applications running on Amazon EC2 instances within an Amazon VPC environment.
Events - DAX records events within your clusters, such as a failure to add a node, success in adding a node, or changes to security groups. Events could be sent to an SNS topic.
- Horizontal Scaling With horizontal scaling, you can `improve throughput
for read operations by adding more read replicas (up to 10`) to the cluster.
You can add or remove replicas while the cluster is running.
- Vertical Scaling Your application might benefit from a larger node type if:
you have a large working data set or your cluster has a high rate of write operations/cache misses.
-
You can’t modify the node types on a running DAX cluster. Instead, you must create a new cluster with the desired node type.
-
Automated Monitoring -
Amazon CloudWatch Alarms,Amazon CloudWatch Logs,Amazon CloudWatch Events,AWS CloudTrail Log Monitoring. -
A user could have access to a DynamoDB table via DAX but not have direct access to the same table.
-
DAX does not enforce user-level separation on data in DynamoDB. Instead, users inherit the permissions of the DAX cluster’s IAM policy when they access that cluster. If you require isolation, we recommend that you create additional DAX clusters and scope the IAM policy for each cluster accordingly
-
Grant access for DAX to access DynamoDB- Create service role (containing a trust relationship specifying which entities can assume the role - in this case DAX)
- Attach a IAM policy to the service role (Policy describes what actions are permitted)
-
Grant access for an IAM user/role to access DAX cluster.- Create an IAM policy that defines the DAX clusters and the DAX API actions that the policy recipient can access/perform.
- Then attach the policy to any IAM user/role you want.
-
DAX encryption at rest cannot be disabled. Is not supported fordax.r3.*node types. -
Allow account B access DAX cluster running in Account A. (Requires admin access in both AWS accounts)
- Launch an EC2 instance in account B with an IAM role from account B.
- Use temporary security credentials from the EC2 instance to assume an IAM role from account A.
- Make application calls over an Amazon VPC peering connection to the DAX cluster in account A
-
You can switch between the AWS owned CMK, AWS managed CMK, and customer managed CMK at any given time.
-
Server-side encryption at rest is enabled on all DynamoDB table data and cannot be disabled.
-
DynamoDB streams are always encrypted with a table-level encryption key.
-
Local secondary indexes and global secondary indexes are encrypted using the same key as the base table.
-
Global tables can be encrypted using an AWS owned CMK or AWS managed CMK.
-
You cannot use a customer managed CMK:
- To encrypt global tables.
- With DynamoDB Accelerator (DAX) clusters
-
DynamoDB Billing:
Data storage,Standard internet transfer fees,Read and write throughput -
You are charged by the hour for the throughput capacity, whether or not you are sending requests to your table. -
Minimum - Maximum throughput one can provision = 1 - practically unlimited.
-
Design your application for uniform activity across all logical partition keys in the table and its secondary indexes.
-
Prefer global secondary indexes over local secondary indexes. The exception is, for:
- Strong consistency - local secondary indexes. Eventual consistency - global secondary indexes.
-
Keep the number of indexes to a minimum. Don’t create secondary indexes on attributes that you don’t query often.
-
NoSQL (e.g DynamoDB) - low-latency response to high-traffic queries.
-
Avoid hardcoding your AWS credentials. Rather use Amazon Cognito as it uses
IAM roles to generate temporary credentials for your application’s authenticated and unauthenticated users.
- You can copy data from a DynamoDB table into Amazon Redshift, to perform
complex data analysis queries.
- Amazon DynamoDB is integrated with Apache Hive, a data warehousing application
that runs on Amazon EMR.