Aurora
You can bring data from Amazon RDS for MySQL and Amazon RDS for PostgreSQL into Aurora by:
- Creating and restoring snapshots
- Setting up one-way replication.
- Using push-button migration tools to convert your existing applications to Aurora.
Aurora cluster
Aurora Cluster Architecture
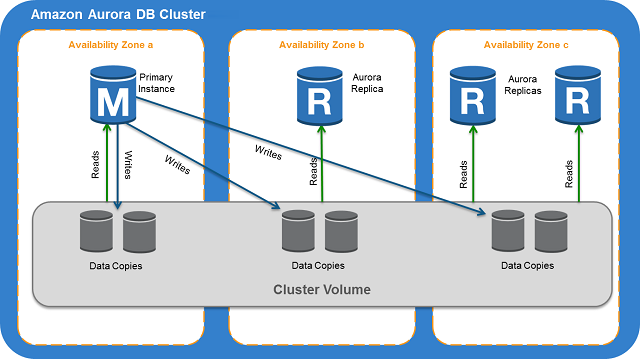
Aurora Cluster Architecture. Source: docs.aws.amazon.com/AmazonRDS
-
1 primary instance + up to 15 replicas (read only) sharing same cluster volume.
-
Cluster volume:
- Single, virtual volume that uses solid state drives (SSDs)
- Multi-AZ. Each AZ has a copy of DB cluster data.
-
Single master clusters: Aurora Serverless, Parallel query, Global Database.
-
For multi-master clusters, all DB instances have read-write capability.
In this case, the distinction between primary instance and Replica doesn’t apply.
- To create a multi-master cluster, you choose Multiple writers under Database features when creating the cluster.
2 Node Aurora Multi-master Architecture

2 Node Aurora Multi-master Architecture. Source: aws.amazon.com/blogs/database
Notes
- Aurora doesn’t support local zones.
- Primary instance handles all data definition language (DDL) and data
manipulation language (DML) statements. Up to 15 Aurora Replicas handle read-only query traffic.
Amazon Aurora typically involves a cluster of DB instances instead of a single instance. Each connection is handled by a specific DB instance. When you connect to an Aurora cluster, the host name and port that you specify point to an intermediate handler called an endpoint. Aurora uses the endpoint mechanism to abstract these connections. Thus, you don’t have to hardcode all the hostnames or write your own logic for load-balancing and rerouting connections when some DB instances aren’t available.
Using endpoints, you can map each connection to the appropriate instance or group of instances based on your use case.
- A cluster endpoint (or writer endpoint) for an Aurora DB cluster connects to the current primary DB instance for that DB cluster. This endpoint is the only one that can perform write operations such as DDL statements
Each Aurora DB cluster has one cluster endpoint and one primary DB instance.
-
A reader endpoint for an Aurora DB cluster provides load-balancing support for read-only connections to the DB cluster. Use the reader endpoint for read operations, such as queries.
-
A custom endpoint for an Aurora cluster represents a set of DB instances that you choose. When you connect to the endpoint, Aurora performs load balancing and chooses one of the instances in the group to handle the connection
-
An instance endpoint connects to a specific DB instance within an Aurora cluster.
Db Instance Class Types
Amazon Aurora supports two types of instance classes:
- Memory Optimized:
db.r3previous,db.r4current,db.r5latest generation. - Burstable Performance:
db.t2current,db.t3latest generation.
Crash Recovery
Aurora is designed to recover from a crash almost instantaneously and continue to serve your application data without the binary log. Aurora performs crash recovery asynchronously on parallel threads, so that your database is open and available immediately after a crash.
- Aurora does not need the binary logs to replicate data within a DB cluster or
to perform point in time restore (PITR).
- Reduce recovery time by setting the
binlog_formatparameter toOFFif
you don’t need the binary log for external replication.
Amazon Aurora Global Databases
An Aurora global database consists of one primary AWS Region where your data is mastered, and up to five read-only, secondary AWS Regions. Aurora replicates data to the secondary AWS Regions with typical latency of under a second. You issue write operations directly to the primary DB instance in the primary AWS Region.
- You have a choice of using db.r4 or db.r5 instance classes for an Aurora
global database. You can’t use db.t2 or db.t3 instance classes.
-
A secondary cluster must be in a different AWS Region than the primary cluster.
-
To upgrade your global database clusters, you must upgrade the secondary clusters before the primary cluster.
-
You can start a Database Activity Stream only on the primary cluster, not on any secondary clusters
-
The following features aren’t supported for Aurora global databases:
-
Cloning.
-
Backtrack.
-
Parallel query.
-
Aurora Serverless.
-
Stopping and starting the DB clusters within the global database.
-
Aurora Replicas
-
You can’t create an encrypted Aurora Replica for an unencrypted Aurora DB cluster.
-
You can’t create an unencrypted Aurora Replica for an encrypted Aurora DB cluster.
Replica lag: Regional < 1 second, Zonal < 100 milliseconds
Managing an Aurora DB cluster
Starting and Stopping
During periods where you don’t need an Aurora cluster, you can stop all instances in that cluster at once. You can start the cluster again anytime you need to use it.
- Aurora automatically starts your DB cluster after seven days so that it doesn’t
fall behind any required maintenance updates.
- You can’t stop an individual Aurora DB instance.
Storage
- Storage costs are based on the storage “high water mark,” the maximum amount
that was allocated for the Aurora cluster at any point in time.
-
Creating and restoring a snapshot does not reduce the allocated storage
-
To reduce cost, avoid extract, transform, load (ETL) practices that create large volumes of temporary information.
Cloning
-
You can make multiple clones from the same DB cluster.
-
You can also create additional clones from other clones.
-
You cannot create clone databases across AWS regions. The clone databases must be created in the same region as the source databases.
Auto Scaling
Aurora Auto Scaling dynamically adjusts the number of Aurora Replicas provisioned for an Aurora DB cluster using single-master replication. You define and apply a scaling policy to an Aurora DB cluster. The scaling policy defines the minimum and maximum number of Aurora Replicas that Aurora Auto Scaling can manage. You can enable or disable scale-in activities for a policy.
-
Although Aurora Auto Scaling manages Aurora Replicas, the Aurora DB cluster must start with at least one Aurora Replica.
-
Aurora Auto Scaling only scales a DB cluster if all Aurora Replicas in a DB cluster are in the available state.
-
When a scale-in or a scale-out cooldown period is not specified, the default for each is 300 seconds.
Backup and Restore
If the primary instance in a DB cluster using single-master replication fails, Aurora automatically fails over to a new primary instance in one of two ways:
-
By promoting an existing Aurora Replica to the new primary instance
-
By creating a new primary instance
Aurora backs up your cluster volume automatically and retains restore data for the length of the backup retention period. Aurora backups are continuous and incremental so you can quickly restore to any point within the backup retention period. No performance impact or interruption of database service occurs as backup data is being written. You can specify a backup retention period, from 1 to 35 days, when you create or modify a DB cluster.
-
To control your backup storage usage, you can reduce the backup retention interval, remove old manual snapshots when they are no longer needed, or both.
-
You can’t restore a DB cluster from a DB cluster snapshot that is both shared and encrypted. Instead, you can make a copy of the DB cluster snapshot and restore the DB cluster from the copy.
Copying a Snapshot
-
After you copy a snapshot, the copy is a manual snapshot.
-
As an alternative to copying, you can also share manual snapshots with other AWS accounts.
-
If you are copying an encrypted snapshot that has been shared from another AWS account, you must have access to the KMS encryption key that was used to encrypt the snapshot.
-
You can only copy a shared DB cluster snapshot, whether encrypted or not, in the same AWS Region.
Sharing a DB Cluster Snapshot
- Sharing a manual DB cluster snapshot, whether encrypted or unencrypted,
enables authorized AWS accounts to:
-
Copy the snapshot.
-
Directly restore a DB cluster from the snapshot instead of taking a copy
of it and restoring from that.
- You can share DB cluster snapshots that have been encrypted “at rest” by
taking the following steps:
- Share the AWS KMS encryption key that was used to encrypt the snapshot
with any accounts that you want to be able to access the snapshot.
- You can share AWS KMS encryption keys with another AWS account by adding
the other account to the KMS key policy
-
You can’t share encrypted snapshots as public.
-
You can’t share a snapshot that has been encrypted using the default AWS
KMS encryption key of the AWS account that shared the snapshot.
Exporting DB Snapshot Data to Amazon S3
You can export manual snapshots and automated system snapshots. By default, all data in the snapshot is exported. However, you can choose to export specific sets of databases, schemas, or tables.
Restoring a DB Cluster to a Specified Timestream
Restoring a DB cluster to a specific point in time, creates a new DB cluster.
Rebooting a DB Instance in a DB Cluster
- If you make certain modifications, or if you change the DB parameter group
associated with the DB instance or its DB cluster, you must reboot the instance for the changes to take effect.
- You can’t reboot your DB instance if it is not in the
availablestate. Your
database can be unavailable for several reasons, such as an in-progress backup, a previously requested modification, or a maintenance-window action.
- When you reboot the primary instance of an Amazon Aurora DB cluster, RDS also
automatically restarts all of the Aurora Replicas in that DB cluster.
- When you reboot the primary instance of an Aurora DB cluster, no failover
occurs. When you reboot an Aurora Replica, no failover occurs.
Overview of Amazon RDS Resource Tags
An Amazon RDS tag is a name-value pair that you define and associate with an Amazon RDS resource. The name is referred to as the key. Supplying a value for the key is optional.
Monitoring Amazon Aurora
You can use the following automated monitoring tools to watch Amazon Aurora and report when something is wrong:
-
Amazon RDS Events – Subscribe to Amazon RDS events to be notified when changes occur with a DB instance, DB cluster, DB cluster snapshot, DB parameter group, or DB security group.
-
Database log files – View, download, or watch database log files using the Amazon RDS console or Amazon RDS API operations. You can also query some database log files that are loaded into database tables.
-
Amazon RDS Enhanced Monitoring — Look at metrics in
real timefor theoperating system. -
Amazon RDS Performance Insights — Assess the load on your database, and determine when and where to take action.
-
Amazon RDS Recommendations — Look at automated recommendations for database resources, such as DB instances, DB clusters, and DB cluster parameter groups.
In addition, Amazon RDS integrates with Amazon CloudWatch, Amazon EventBridge, and AWS CloudTrail for additional monitoring capabilities:
-
Amazon CloudWatch Metrics – Amazon RDS automatically sends metrics to CloudWatch every minute for each active database. You don’t get additional charges for Amazon RDS metrics in CloudWatch.
-
Amazon CloudWatch Alarms – You can watch a single Amazon RDS metric over a specific time period. You can then perform one or more actions based on the value of the metric relative to a threshold that you set.
-
Amazon CloudWatch Logs – Most DB engines enable you to monitor, store, and access your database log files in CloudWatch Logs.
-
Amazon CloudWatch Events and Amazon EventBridge – You can automate AWS services and respond to system events such as application availability issues or resource changes. Events from AWS services are delivered to CloudWatch Events and EventBridge nearly in real time. You can write simple rules to indicate which events interest you and what automated actions to take when an event matches a rule.
-
AWS CloudTrail – You can view a record of actions taken by a user, role, or an AWS service in Amazon RDS. CloudTrail captures all API calls for Amazon RDS as events. These captures include calls from the Amazon RDS console and from code calls to the Amazon RDS API operations. If you create a trail, you can enable continuous delivery of CloudTrail events to an Amazon S3 bucket, including events for Amazon RDS. If you don’t configure a trail, you can still view the most recent events in the CloudTrail console in Event history.
Performance
Spatial indexing improves query performance on large datasets for queries on spatial data.
You can use the SPATIAL INDEX keywords in CREATE TABLE, ALTER TABLE,
CREATE INDEX statements to add a spatial index to a column in a new table.
Following is an example:
CREATE TABLE test (shape POLYGON NOT NULL, SPATIAL INDEX(shape));Amazon Aurora Basic Operational Guidelines
-
Allocate enough RAM - To optimize performance, allocate enough RAM so that your working set resides almost completely in memory. To determine whether your working set is almost all in memory, examine the following metrics in Amazon CloudWatch:
VolumeReadIOPS: average number of read I/O operations -should be small and stable.BufferCacheHitRatio: percentage of requests served from cache -should be high.
-
Set TTL value of less than 30 seconds - If your client application is caching the Domain Name Service (DNS) data of your DB instances, set a time-to-live (TTL) value of less than 30 seconds. Because the underlying IP address of a DB instance can change after a failover, caching the DNS data for an extended time can lead to connection failures if your application tries to connect to an IP address that no longer is in service. Aurora DB clusters with multiple read replicas can experience connection failures also when connections use the reader endpoint and one of the read replica instances is in maintenance or is deleted.
-
Back up your DB cluster before modifying a DB parameter group.
-
Do not enable the MySQL Performance Schema on Amazon Aurora MySQL T2 instances.
If the Performance Schema is enabled, the T2 instance might run out of memory.
Using Amazon Aurora Recommendations
Amazon Aurora provides automated recommendations for database resources, such as DB instances, DB clusters, and DB cluster parameter groups. These recommendations provide best practice guidance by analyzing DB cluster configuration, DB instance configuration, usage, and performance data.
You can find recommendations in the AWS Management Console. You can perform the recommended action immediately, schedule it for the next maintenance window, or dismiss it.
Database Activity Streams
The collection, transmission, storage, and subsequent processing of the stream of database activity is beyond the access of the DBAs that manage the database.
A stream of database activity is pushed from Aurora to an Amazon Kinesis data stream that is created on behalf of your Aurora DB cluster. From Kinesis, the activity stream can then be consumed by AWS services such as Amazon Kinesis Data Firehose and AWS Lambda, or by applications for compliance management.
Database activity streams require use of AWS Key Management Service (AWS KMS). AWS KMS is required because the activity streams are always encrypted.
Aurora Serverless
When you work with Amazon Aurora without Aurora Serverless (provisioned DB clusters), you can choose your DB instance class size and create Aurora Replicas to increase read throughput. If your workload changes, you can modify the DB instance class size and change the number of Aurora Replicas.
On the other hand,
Aurora Serverless allows you create a database endpoint without specifying the DB instance class size. You set the minimum and maximum capacity. Aurora Serverless database endpoint connects to a proxy fleet that routes the workload to a fleet of resources that are automatically scaled.
- Connections are continous.
- Resources scaled automatially based on minimum and maximum capacity.
- Compatible with existing database client applications.
- Connections are managed
- Scaling is rapid because Aurora Serverless uses a pool of warm resources.
- Storage and processing are scaled separately.
Aurora Capacity Unit (ACU) is a combination of processing and memory capacity.
Aurora Serverless automatically creates scaling rules for thresholds for CPU utilization, connections, and available memory based on your settings for minimum and maximum ACU.
- You can choose to pause your Aurora Serverless DB cluster after a given
amount of time with no activity. 5 minutes is the default.
-
Scales to zero capacity when no connections for 5 minute period.
-
Cool down period for scaling down:
15 minutes- after scaling up.5 minutes- after scaling down. (310 seconds)
-
No cool down period for scaling up.
When you change the capacity, of an Aurora Serverless DB cluster, it tries to find a scaling point for the change. If it can’t find a scaling point, it times out. You can specify one of the following actions to take when a capacity change times out:
-
Force the capacity change – Set the capacity to the specified value as soon as possible.
-
Roll back the capacity change – Cancel the capacity change.
-
Maintenance windows don’t apply to Aurora Serverless .
Aurora Serverless and Snapshots - The cluster volume for an Aurora Serverless
cluster is always encrypted. You can choose the encryption key, but not turn off encryption. To copy or share a snapshot of an Aurora Serverless cluster, you encrypt the snapshot using your own KMS key.
Aurora Serverless and Failover
If the DB instance for an Aurora Serverless DB cluster becomes unavailable or the Availability Zone (AZ) it is in fails, Aurora recreates the DB instance in a different AZ. We refer to this capability as automatic multi-AZ failover.
This failover mechanism takes longer than for an Aurora Provisioned cluster. The Aurora Serverless failover time is currently undefined because it depends on demand and capacity availability in other AZs within the given AWS Region.
Because Aurora separates computation capacity and storage, the storage volume for the cluster is spread across multiple AZs. Your data remains available even if outages affect the DB instance or the associated AZ.
Takeaways
-
Aurora Properties:
- Auto-scales up to 64TB per database instance.
- Point-in-time recovery
- Continuous backup to Amazon S3
- Replication across three Availability Zones (AZs).
-
1 primary instance + up to 15 replicas (read only) sharing same cluster volume.
-
Cluster volume is multi-AZ. Each AZ has a copy of DB cluster data.
-
For multi-master clusters, all DB instances have read-write capability.
-
Each Aurora DB cluster has one cluster endpoint and one primary DB instance.
-
Crash recovery done asynchronously on parallel threads, so that your database
is open and available immediately after a crash.
- Reduce recovery time by setting the
binlog_formatparameter toOFFif
you don’t need the binary log for external replication.
-
Supplying a value for an RDS resource tag key is optional.
-
A secondary cluster must be in a different AWS Region than the primary cluster.
-
The following features aren’t supported for Aurora global databases:
Cloning,Backtrack,Parallel query,Aurora Serverless. -
Replica lag: Regional < 1 second, Zonal < 100 milliseconds
-
If you stop your DB cluster, Aurora automatically starts your DB cluster after
seven days so that it doesn’t fall behind any required maintenance updates.
-
You can’t stop an individual Aurora DB instance.
-
300 seconds = Default scale-in or a scale-out cooldown period.
-
1 - 35 days - The rang you can specify for retention period of automatic
backups, when you create or modify a DB cluster.
- You can’t restore a DB cluster from a DB cluster snapshot that is both shared
and encrypted. Instead, you can make a copy of the DB cluster snapshot and restore the DB cluster from the copy.
- If you are copying an encrypted snapshot that has been shared from another
AWS account, you must have access to the KMS encryption key that was used to encrypt the snapshot.
-
You can only copy a shared DB cluster snapshot, whether encrypted or not, in the same AWS Region.
-
You can’t share encrypted snapshots as public.
-
You can’t share a snapshot that has been encrypted using the default AWS
KMS encryption key of the AWS account that shared the snapshot.
-
Spatial indexing improves query performance on large datasets for queries on spatial data.
-
You can use the SPATIAL INDEX keywords in
CREATE TABLE,ALTER TABLE,
CREATE INDEX statements.
- To optimize performance, allocate enough RAM so that your working set resides
almost completely in memory.
- Set TTL value of less than 30 seconds, if your client application is caching
the Domain Name Service (DNS) data of your DB instances.
- The collection, transmission, storage, and subsequent processing of the stream
of database activity is beyond the access of the DBAs that manage the database.
- A stream of database activity is pushed from Aurora to an Amazon Kinesis data
stream that is created on behalf of your Aurora DB cluster.
-
Database activity streams require use of AWS Key Management Service (AWS KMS).
-
AWS KMS is required because the activity streams are
always encrypted. -
Aurora Serverless allows you create a database endpoint without specifying the
DB instance class size. You set the minimum and maximum capacity. Aurora Serverless auto scales.
-
Compatible with existing database client applications.
-
Connections are managed
-
Scaling is rapid because Aurora Serverless uses a pool of warm resources.
-
Storage and processing are scaled separately.
- You can choose to pause your Aurora Serverless DB cluster after a given
amount of time with no activity. 5 minutes is the default.
-
Cool down period for scaling down Aurora Serverless:
-
15 minutes- after scaling up. -
5 minutes- after scaling down. (310 seconds)
-
-
No cool down period for scaling up Aurora Serverless.
-
When a Aurora Serverless capacity change times out, you can specify one of the following:
-
Force the capacity change – Set the capacity to the specified value as soon as possible.
-
Roll back the capacity change – Cancel the capacity change.
-
-
Maintenance windows don’t apply to Aurora Serverless .
-
Cluster volume for an Aurora Serverless cluster is always encrypted. You can
choose the encryption key.
- To copy or share a snapshot of an Aurora Serverless cluster,
you encrypt the snapshot using your own KMS key.
- If Aurora Serverless DB cluster becomes unavailable or the AZ it is in fails,
Aurora recreates the DB instance in a different AZ. Amazon refers to this
as Automatic multi-AZ failover. It takes longer than provisioned cluster